[시각화] 서울 스타벅스 매장을 지도에 찍어보자
이번 시간에는 스타벅스 홈페이지에서 정보들을 크롤링해서 서울시의 모든 매장을 서울시 지도에 표시해보겠습니다.
1
2
3
4
5
6
!pip install selenium
from selenium import webdriver #크롤링
from bs4 import BeautifulSoup #분석
import pandas as pd
import numpy as np
!pip install folium
필요한 툴들은 임포트하고 설치했습니다.
1
2
driver = webdriver.Chrome('star.exe')
driver.get("https://www.starbucks.co.kr/store/store_map.do")
먼저 인터넷에서 크롬 웹드라이버를 설치하고 불러왔습니다. 그리고 get()메서드로 스타벅스 메인 홈페이지를 연결했습니다.
우리는 이 홈페이지에서 우측 상단에 find a store를 눌러야합니다. 물론 홈페이지에서 누를 수 도 있지만 파이썬으로 해봅시다.
1
2
3
4
area_btn= '#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a'
driver.find_element_by_css_selector(area_btn).click()
클릭을 원하는 단추 코드 찾는 방법입니다.
단추 위에서 - 우클릭 - 검사 - 우클리 - 또검사를 하면 해당 코드 위에서 우클릭 - copy - copy selector 해서 저 html코드를 불러올 수 있습니다.
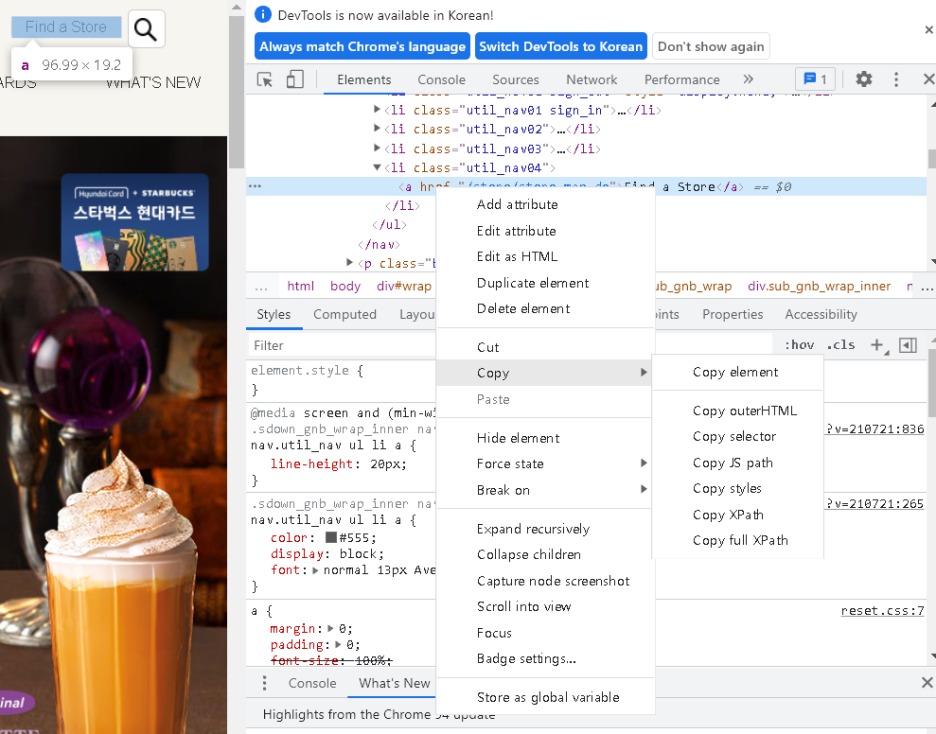 보시면 저기에 copy selector가 있죠? 저걸 누르고 area_btn이란 변수에 저것은 문자열로 넣었습니다. 그리고 driver객체에 있는 find_element_by_css_selector()메서드에 인자로 저 변수를 넣고 .click()으로 클릭을 실행하게 했습니다. 이 코드를 실행하면 저것을 클릭하는 것이죠. 앞으로 이방법을 몇 번 쓸겁니다. 클릭을 몇번 해야해서 ㅎㅎ
보시면 저기에 copy selector가 있죠? 저걸 누르고 area_btn이란 변수에 저것은 문자열로 넣었습니다. 그리고 driver객체에 있는 find_element_by_css_selector()메서드에 인자로 저 변수를 넣고 .click()으로 클릭을 실행하게 했습니다. 이 코드를 실행하면 저것을 클릭하는 것이죠. 앞으로 이방법을 몇 번 쓸겁니다. 클릭을 몇번 해야해서 ㅎㅎ
1
2
seoul_btn='#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a'
driver.find_element_by_css_selector(seoul_btn).click()
이번엔 매장찾기에 들어가면 지역을 선택하는게 있습니다. 서울지역을 할거라서 아까와 마찬가지로 서울 버튼을 우클릭해서 html코드를 문자열로 받아왔습니다. 그리고 click()으로 클릭!
1
2
total_btn ='#mCSB_2_container > ul > li:nth-child(1) > a'
driver.find_element_by_css_selector(total_btn).click()
그리고 서울 탭 안에 ‘전체’라는 탭이 있습니다. 모든 매장을 지도에 표시할거라서 전체탭을 클릭했습니다.
1
2
html = driver.page_source
soup = BeautifulSoup(html,"html.parser")
저렇게 전체 탭을 클릭하면 서울시의 전체 매장이 뜨겠죠? 그 순간의 페이지의 정보를 driver의 page_source로 가져와서 html이란 변수에 넣었습니다. 그리고 BeautifulSoup()라는 메서드가 보이는데요. 이것은 웹 스크래핑에 사용되는 파이썬 패키지입니다. 거기에 정보가 담겨있는 html을 인자로 넣고 html코드로 변형해서 soup라는 변수에 넣었습니다.
 soup를 프린트하면 이렇게 html코드로 나오네요 ㅎ
soup를 프린트하면 이렇게 html코드로 나오네요 ㅎ
1
2
starbucks_soup_list =soup.select("li.quickResultLstCon")
starbucks_soup_list
그리고 홈페이지에서 관리자모드로 코드를 보시면 각각의 매장이 <li> 태그로 되어있습니다.그리고 class는 quickResultLstCon이군요. 그래서 이것들을 다 선택한 뒤 그것을 starbucks_soup_list라는 변수에 넣었습니다.
1
print(starbucks_soup_list[0])
 저기 중에 첫번재 인덱스를 가져왔습니다. 보시면 하나의 매장에 대한 정보가 쭉 있는데요, 여기서 우리는 매장이름과 주소와 연락처를 가져오려고 합니다. 이름을 보시면 태그에 있는 것을 확인할 수 있습니다. 여기서 매장명만 가져오고 싶습니다.
저기 중에 첫번재 인덱스를 가져왔습니다. 보시면 하나의 매장에 대한 정보가 쭉 있는데요, 여기서 우리는 매장이름과 주소와 연락처를 가져오려고 합니다. 이름을 보시면 태그에 있는 것을 확인할 수 있습니다. 여기서 매장명만 가져오고 싶습니다.
1
2
3
name = starbucks_store.select('strong')[0].text.strip()
print(name)
그냥 strong을 가져오면 원소가 하나만 있는 리스트의 형태로 나옵니다. 따라서 첫번째 인덱스를 가져와서 리스트가 아닌 원소를 가져오는 거죠. 그리고 거기에 text로 텍스트만 가져오게 했습니다.
 잘 나오네요 ㅎㅎ 집근처가 1번인가봐요 ㅋㅋ 이번엔 위도와 경도를 가져오겠습니다.
잘 나오네요 ㅎㅎ 집근처가 1번인가봐요 ㅋㅋ 이번엔 위도와 경도를 가져오겠습니다.
1
2
3
4
5
lat = starbucks_store['data-lat'].strip()
lng = starbucks_store['data-long'].strip()
print(lat)
print(lng)
여기서 딕셔너리의 형태로 되어있어서 각각 키값을 입력해서 위도와 경도를 출력합니다.
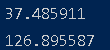 이겁니다. 이제 이 정보로 각각의 매장을 지도에 찍을겁니다!
이겁니다. 이제 이 정보로 각각의 매장을 지도에 찍을겁니다!
``` add = str(starbucks_store.select(‘p.result_details’)[0]).split(‘
’)[0].split(‘>’)[1] print(add) tel = str(starbucks_store.select(‘p.result_details’)[0]).split(‘
’)[1].split(‘<’)[0] print(tel)
1
2
3
4
5
6
마찬가지로 태그와 split()을 통해서 주소와 전화번호도 가져왔습니다!

잘나오네요 ㅎㅎ 자 이렇게 한 매장에 대한 정보를 가져오는 법을 알았으니 전체 매장을 가져와야겠죠?
starbucks_list =[] for item in starbucks_soup_list: name = item.select(‘strong’)[0].text.strip() lat = item[‘data-lat’].strip() lng = item[‘data-long’].strip() add = str(item.select(‘p.result_details’)[0]).split(‘
’)[0].split(‘>’)[1] tel = str(item.select(‘p.result_details’)[0]).split(‘
’)[1].split(‘<’)[0]
1
starbucks_list.append([name,lat,lng,add,tel]) ```
for문으로 starbucks_soup_list의 모든 원소의 정보를 리스트로 묶 어서 starbucks_list 에 하나씩 추가했습니다.
1
2
3
4
5
columns=['매장명','위도','경도','주소','전화번호']
seoul_starbucks_df = pd.DataFrame(starbucks_list,columns=columns)
seoul_starbucks_df
각각을 컬럼명으로 만들어서 모든 정보가 들어있는 starbucks_list를 DataFrame() 로 컬럼명을 컬럼으로 설정하여 seoul_starbucks_df 를 만들었습니다.
1
seoul_starbucks_df.to_excel('seoul_starbucks_list.xls',index=False)
그리고 이것을 엑셀로 변환하여 저장했습니다.
이번엔 서울시의 인구통계정보를 가져와서 우리가 만든 정보랑 합쳐보겠습니다!
1
2
3
import pandas as pd
sgg_pop_df = pd.read_csv('report_people_seoul.txt',sep='\t',header=2)
sgg_pop_df
sgg_pop_df라는 변수를 만들어 여기에서 받아온 파일은 read_csv()로 정보를 가져왔습니다. 여기는 콤마가 아닌 탭으로 정보가 나뉘어져있어서 sep=’/t’을 옵션으로 주었습니다!
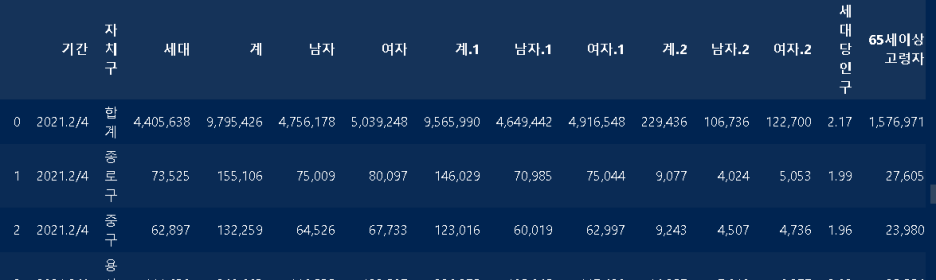 뭐 이런식으로 구별로 인구수가 나옵니다.
뭐 이런식으로 구별로 인구수가 나옵니다.
1
2
seoul_starbucks=pd.read_excel('seoul_starbucks_list.xls',header=0)
seoul_starbucks
그리고 아까 엑셀로 변환한 파일을 다시 읽어서 seoul_starbucks라는 변수에 넣었습니다
 이런식으로 쭈우욱 나와있네요 ㅎㅎ이제 여기서 인구통계도 구별로 나와있으니 이것도 구만 뽑아봅시다
이런식으로 쭈우욱 나와있네요 ㅎㅎ이제 여기서 인구통계도 구별로 나와있으니 이것도 구만 뽑아봅시다
1
2
3
4
5
6
7
sgg_names=[]
for add in seoul_starbucks['주소']:
sgg= add.split()[1]
sgg_names.append(sgg)
sgg_names
sgg_names리스트를 만들고 for문으로 주소키값을 하나씩 가져와서 split()으로 구만 다 가져와서 리스트에 넣었습니다
 잘 나오네요 ㅎㅎ 이제 이것을 아까 seoul_starbucks에 새로운 컬럼을 추가해서 이 정보를 넣어보겠습니다
잘 나오네요 ㅎㅎ 이제 이것을 아까 seoul_starbucks에 새로운 컬럼을 추가해서 이 정보를 넣어보겠습니다
1
2
3
seoul_starbucks['시군구명'] = sgg_names
seoul_starbucks
이러면 원래있던 데이터에서 시군구명이라는 열이 생기고 각 구가 들어가겠죠?이제 또 구별로 주민등록인구 파일을 받아서 이것의 정보를 가져오겠습니다.
1
2
seoul_sgg = pd.read_excel('sgg_pop.xlsx')
seoul_sgg
 이런식으로 구와 그 구의 인구수를 가져왔습니다. 이제 아까 seoul_starbucks에서 구별로 매장수를 집계해보겠습니다.
이런식으로 구와 그 구의 인구수를 가져왔습니다. 이제 아까 seoul_starbucks에서 구별로 매장수를 집계해보겠습니다.
1
2
3
starbucks_sgg_count=seoul_starbucks.pivot_table(index='시군구명',values='매장명',aggfunc='count')
starbucks_sgg_count
pivot_table()로 시군구명을 인덱스로하고 매장명을 aggfunc=옵션으로 ‘count’로 해서 각 구별로 매장수를 알아보려고 합니다.
 잘나오네요 ㅎㅎ 역시 강남구가 제일 많을듯 하네요. 이제 아까 만들었던 seoul_sgg(구별 총 인구수)와 지금 이 데이터를 합쳐보겠습니다.
잘나오네요 ㅎㅎ 역시 강남구가 제일 많을듯 하네요. 이제 아까 만들었던 seoul_sgg(구별 총 인구수)와 지금 이 데이터를 합쳐보겠습니다.
1
2
3
seoul_sgg=pd.merge(seoul_sgg,starbucks_sgg_count,how='left',on='시군구명')
seoul_sgg
merge()로 각각 데이터 이름을 넣고, on=옵션으로 둘다 일치하는 컬럼명 시군구명을 넣었습니다.
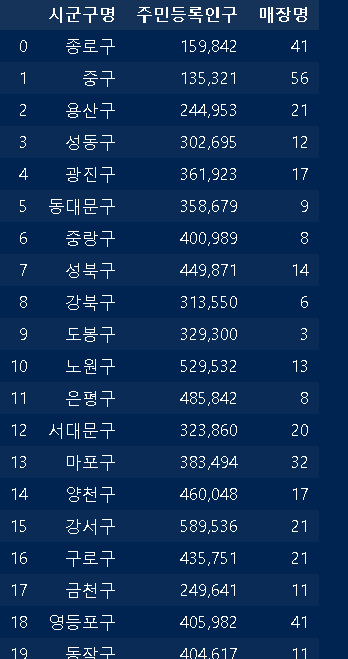 잘 나오네요 ㅎㅎ 그리고 이번엔 sgg_biz파일을 받았습니다. 이것은 각 구별로 종사자수와 사업체수를 갖고있는 정보입니다. 마찬가지로 합쳐줍시다
잘 나오네요 ㅎㅎ 그리고 이번엔 sgg_biz파일을 받았습니다. 이것은 각 구별로 종사자수와 사업체수를 갖고있는 정보입니다. 마찬가지로 합쳐줍시다
1
2
3
4
seoul_biz=pd.read_excel("sgg_biz.xlsx")
seoul_sgg=pd.merge(seoul_sgg, seoul_biz,how='left',on='시군구명')
seoul_sgg
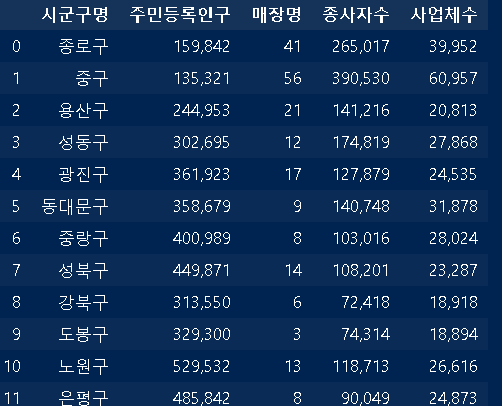 매장수에 이어 종사자수와 사업체수도 나오군요 ㅎㅎ 재밌습니다
매장수에 이어 종사자수와 사업체수도 나오군요 ㅎㅎ 재밌습니다
1
seoul_sgg.to_excel('seoul_sgg.xlsx',index=False)
그리고 다시 이 데이터를 엑셀로 변환하여 저장했습니다. 이제 지도를 그려봅시다!!
1
2
seoul_starbucks=pd.read_excel('seoul_starbucks_list.xls')
seoul_starbucks
아까 엑셀로 저장했던 seoul_starbucks_list를 가져왔습니다. 여기엔 매장명 위도 경도 주소 전화번호가 있죠?
그 다음엔 먼저 서울지도를 가져옵니다. 이것은 folium으로 하는데 그냥 folium.Map()을 해버리면 세계지도 나옵니다.. 그래서 서울만 딱 포커스해보겠습니다.
1
2
starbucks_map=folium.Map(location=[37.55,126.99],zoom_start=11,tiles="stamen Terrain")
starbucks_map
location에 서울의 위도와 경도를 입력하고 zoom_start를 11로주었습니다. 이렇게 하면 서울을 딱 줌해서 나옵니다. tiles=옵션을 주어서 지형지물 지도로 나타내겠습니다
 크…! 잘나옵니다 멋있네요 ㅎㅎ 이제 여기에 매장을 찍어봅시다
크…! 잘나옵니다 멋있네요 ㅎㅎ 이제 여기에 매장을 찍어봅시다
1
2
3
4
5
6
7
8
9
10
for idx in seoul_starbucks.index:
lat = seoul_starbucks.loc[idx,'위도']
lng= seoul_starbucks.loc[idx,'경도']
folium.CircleMarker(
location=[lat,lng],fill=True,fill_color='green',fill_opacity=1,color='yellow',
weight=1,radius=3, size=1,
).add_to(starbucks_map)
starbucks_map
for문으로 각각의 행(매장)의 위도와 경보를 가져와서 folium의 CircleMarker()를 통해서 각각 좌표에 점을 찍을겁니다. 그리고 뭐 각자의 기호대로 옵션을 준 뒤 add_to()메서드로 starbucks_map 맵에 추가할겁니다.
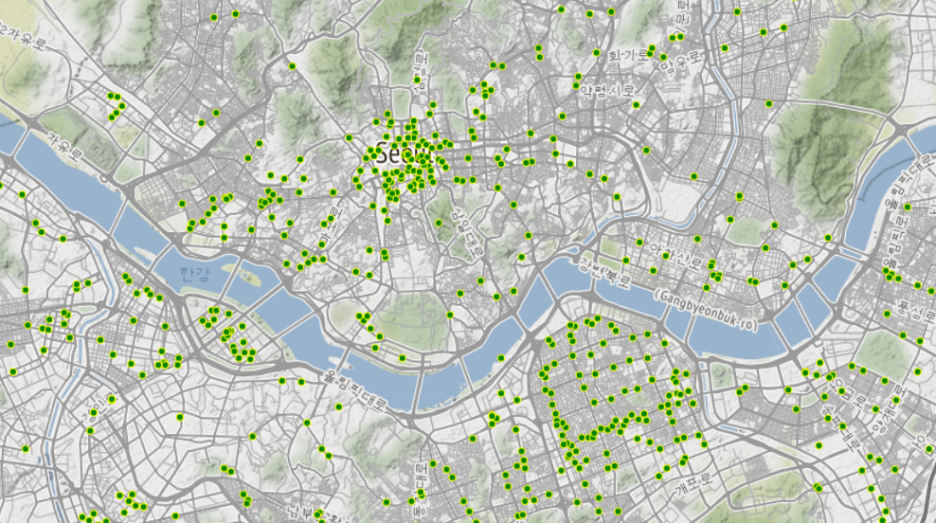 키야!! 대박입니다ㅎㅎ 역시 종로쪽과 강남쪽에 제일 많이 분포되어있군요!!
키야!! 대박입니다ㅎㅎ 역시 종로쪽과 강남쪽에 제일 많이 분포되어있군요!!
이번 시간에는 여기까지 하겠습니다~
Comments powered by Disqus.