[R] R로 데이터 분석하기
이번 시간에는 유명한 통계 분석 프로그램인 R을 써보겠습니다! 기본적인 문법은 좀 빠르게 넘어갈게요!
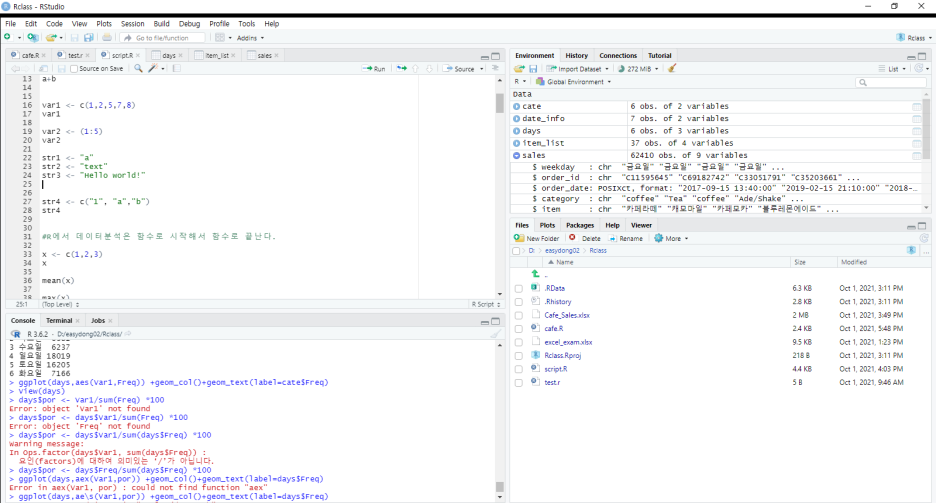
왼쪽 상단이 우리가 주로 쓰는 파트입니다. 오른쪽에는 Data탭이있는데 우리가 만든 변수들이나 데이터프레임을 조회할 수 있습니다. 왼쪽아래는 콘솔이고 오른쪽 아래는 파일탭입니다!
1
2
3
4
5
6
7
8
9
10
11
12
var1 <- c(1,2,5,7,8)
var1
var2 <- (1:5)
var2
str1 <- "a"
str2 <- "text"
str3 <- "Hello world!"
str4 <- c("1", "a","b")
R에서는 <-로 대입연산자를 씁니다. 문자열을 넣을 수 있고 (1:5)처럼 범위도 되고, c()로 배열처럼 만들 수 있습니다. 물론 여기에는 숫자 뿐만 아니라 문자열도 들어갑니다.
1
2
3
4
5
mean(x)
max(x)
min(x)
각각 평균, 최대값,최소값을 반환하는 함수들입니다.
1
2
3
4
5
# 패키지 설치
install.packages("ggplot2")
#임포트
library(ggplot2)
ggplot2를 설치하고 임포트했습니다. 이것으로 데이터 시각화가 가능합니다.
1
2
3
x <- c("a","b","a","c")
x
qplot(x)
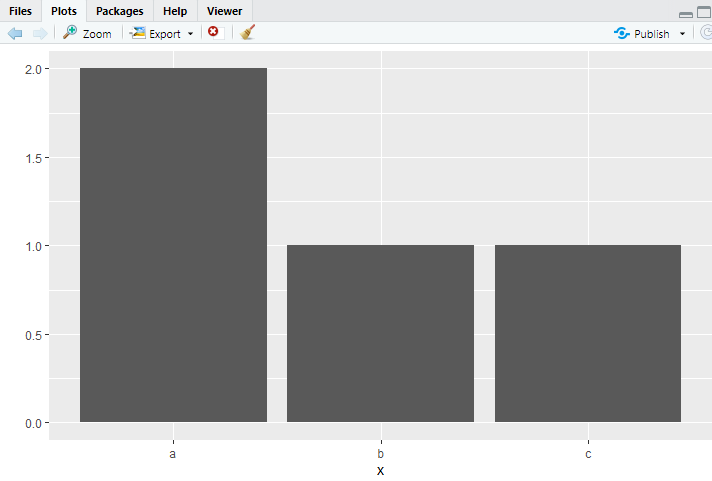
qplot()에 배열을 넣었습니다. a가 2개있어서 저런식으로 막대그래프로 표현한 모습입니다 ㅎㅎ
1
qplot(data = mpg, x= drv, y= hwy, geom = "boxplot", colour = drv)
R 내장 데이터인 mpg를 data로 넣고 x축은 drv? 또 y축은 hwy네요 geom은 또 뭔지.. 그래서 명령어가 있습니다.
1
?mpg
물음표를 앞에 붙이면 마치 javadoc같이 문서로 볼 수 있습니다.

mpg는 차에 관한 데이터프레임이었습니다. 그리고 drv는 구동방식인거같네요, hwy는 고속도로에서의 연비를 나타냅니다. geom은 잘 모르겠지만 추측하자면 geometric? 의 약자가 아닐지.. 아무튼 역할은 플롯의 형태를 정하는 옵션입니다. 색은 x축에 따라서 바뀌게 해놨네요 볼까요?
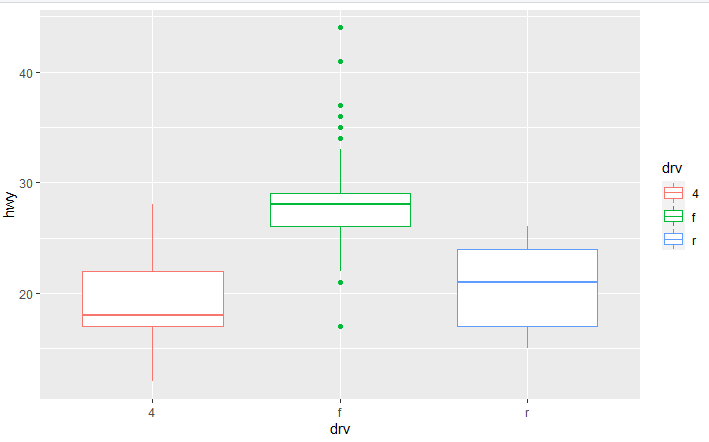
잘 나오네요 ㅎㅎ 박스플롯은 파이썬에서도 표현했었죠? 일종의 주식차트와 같습니다.
1
2
3
4
5
6
7
8
9
10
eng <- c(90,80,60,70)
math <- c(50,60,90,30)
class <- c(1,1,2,2)
df_mid = data.frame(eng,math,class)
df_mid
mean(df_mid$eng)
mean(df_mid$math)
eng과 math 과 class라는 라는 변수를 만들어 이 셋을 data.frame()으로 묶었습니다. 그리고 그중에 영어와 수학성적의 평균을 내고 싶은데요 함수는 mean()을 일단 쓰는데 그 값은 어떻게 할까요? df_mid$eng로 $를 기준으로 그 뒤에 원하는 키값? 같은 것을 가져오면 됩니다.
1
2
3
install.packages('readxl')
library(readxl)
df_exam<- read_excel('excel_exam.xlsx')
이번엔 readxl을 설치하고 임포트하여 엑셀파일을 읽어와 변수 df_exam에 넣었습니다.
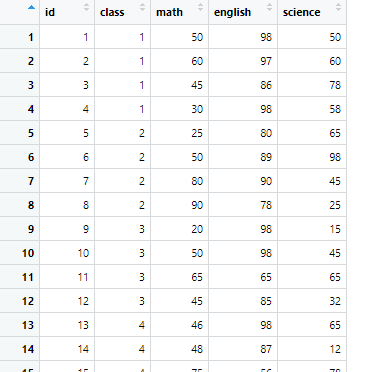
잘 나오네요 ㅎㅎ
1
2
3
4
5
6
head()
tail()
str()
dim()
summary()
View()
head()는 데이터 앞부분을 확인합니다. 각 열을 보여주고 참고로 앞 6개의 행을 보여줍니다. 옵션으로 그 수를 줄이거나 늘일 수 있습니다.
tail()은 head() 반대로 뒤쪽 6개를 보여줍니다.
str()은 데이터의 열값들의 속성과 구조를 파악해줍니다. 마치 SQL 할때 정보를 조회할때랑 비슷합니다.
dim()그 데이터가 몇행 몇열로 구성되어 있는지 확인합니다.
summary()는 변수들의 값을 요약해서 보여줍니다. 평균이나 최대, 최소 등을 보여줍니다.
View()는 그 파일을 열어서 보여줍니다. 주의할 점은 V는 대문자로 쓰셔야합니다 ㅎㅎ
1
2
3
install.packages("dplyr") # 데이터 가공에 사용되는 패키지
library(dplyr)
다음엔 dplyr를 설치하여 데이터 가공을 해봅시다.
1
df_new <-rename(df_new,v2=var2)
rename()은 데이터프레임 안에 있는 어떤 데이터의 이름을 바꿉니다. var2를 v2로 바꾸는 것입니다.
1
2
3
4
5
6
7
8
9
10
11
#파생변수 만들기
df <- df_raw
df$sum <- df$var1+df$var2
df
mpg_new$total <- (mpg_new$city+mpg_new$highway)/2
mean(mpg_new$total)
이번엔 데이터 프레임안에 새로운 파생변수를 만들어 보겠습니다. 데이터 프레임 df에 sum이라는 변수를 만들고 싶습니다. 여기엔 var1과 var2가 합한 값을 넣고 싶은데요. 대입하는 것처럼 <- 에 각각의 변수를 더해주면 됩니다. 그리고 mpg_new에 있는 city와 highway의 평균을 total이라는 새로운 파생변수로 만들고 싶을 때도 저렇게 하면 됩니다. 그리고 그 total의 전체 평균을 알고 싶다면 mean()을 쓰면 되겠죠?
1
2
mpg_grade <-ifelse(mpg_new$total>=30,'A', ifelse(mpg_new$total >=20,"B","C"))
qplot(mpg_grade)
이번엔 조건문입니다. mpg_grade라는 변수를 만들고 mpg_new에 있는 total이 30이 넘어가면 ‘A’ 20이상이면 ‘B’ 그것도 아니라면 “C” 값을 넣을겁니다.
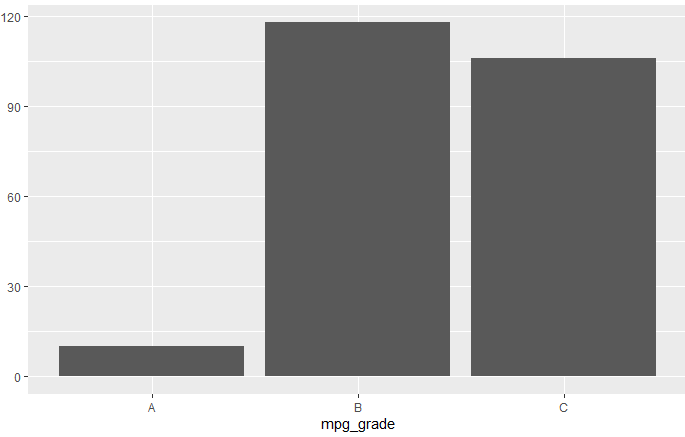
잘 나오네요 ㅎㅎ
이번에는 카페 판매 데이터가 들어있는 엑셀을 가져와서 그정보를 갖고 놀아봅시다
1
2
3
library(readxl)
sales=read_xlsx('Cafe_Sales.xlsx')
sales란 변수에 다운받은 엑셀의 데이터를 넣었습니다.
그전에 먼저 결측치를 제거해야합니다.
1
2
3
4
5
is.na(sales)
table(is.na(sales))
sales <- na.omit(sales)
is.na()가 그 변수 안에 있는 모든 데이터들을 조회하고 null값이 아니라면 False를 반환합니다. 그런데 너무 자료가 많아서 보기가 힘듭니다. 그래서 table()안에 넣어서 간단히 보려고 합니다. 그리고 na.omt()이 결측치를 제거하는 함수인데 여기 인자에 sales를 넣고 그것을 다시 sales에 대입하여 결측치를 제거했습니다.
1
2
3
unique(sales$category)
unique(sales$item)
이것은 unique()함수인데 다른 언어에서도 많이 봤었죠? 중복을 없애고 보여주는 함수입니다. 여기에 caregory와 item을 넣어서 어떤 카테고리가 있는지, 어떤 품목이 있는지 조회해봅시다.
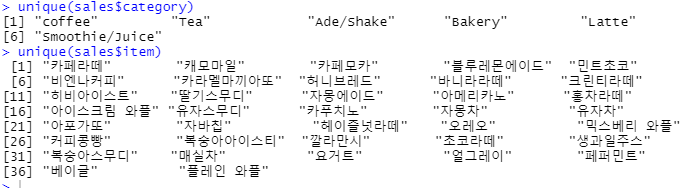
잘 나오네요 ㅎㅎ
이번엔 매출액을 계산하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
sales_tr <- data.frame(table(sales$item))
sales_item <- subset.data.frame(sales,select =c('item','price'))
sales_item <- unique(sales_item)
item_list = merge(sales_tr,sales_item,by.x='Var1',by.y='item')
item_list$amount = item_list$Freq * item_list$price
sum(item_list$amount)
먼저 sales_tr이라는 변수를 만들고 여기에 sales$item을 테이블로 변환하고 다시 그것을 데이터프레임으로 만들고 대입했습니다. 그리고 slaes_item을 만들어서 원래의 sales를 ‘item’과 ‘price’ 2축으로 나누어 저장하고 저장했습니다. 그리고 unique()를 통해서 중복제거를 해주었구요. 그 다음에 item_list를 만들어서 아까 만든 sales_tr과 sales_item을 합쳤습니다. 옵션으로 x축 첫번째는 Var1로 y축은 item으로 정렬했습니다.
그리고 파생변수 amount를 만들어서 여기에 Freq(판매량) * price(가격)을 해서 넣었습니다. 그리고 마지막으로 이 amount를 다 더하면 총 매출액이 나오겠죠? 신기하고 재밌네요 ㅎㅎ
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 요일별 판매 분석
sales$weekday <- weekdays(sales$order_date)
table(sales$weekday)
date_info <- data.frame(weekday = c('월요일','화요일','수요일','목요일','금요일','토요일','일요일'),
day =c('평일','평일','평일','평일','평일','주말','주말'))
sales <- merge(sales,date_info)
View(sales)
table(sales$day)
요일변 판매 분석입니다. sales에 있는 order_date를 weekdays()함수로 그 날짜를 요일로 변환하여 파생변수 weekday에 넣었습니다.
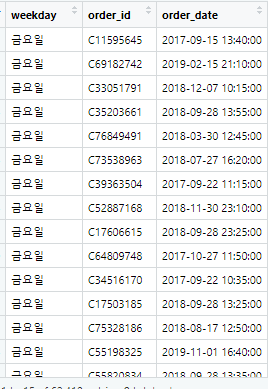
잘 나오네요 ㅎㅎ
그리고 date_info 데이터 프레임을 만들어서 여기에 weekday 열에 각각의 요일 이름을 넣었고, day라는 열에는 평일과 주말을 나눠서 만들었습니다. 그리고 merge()로 이 sales와 data_info를 합치면 sales에 있던 weekday와 date_info에 있던 weekday가 같아서 sales에 있는 weekday의 요일에 맞춰 평일과 주말을 나눴습니다.
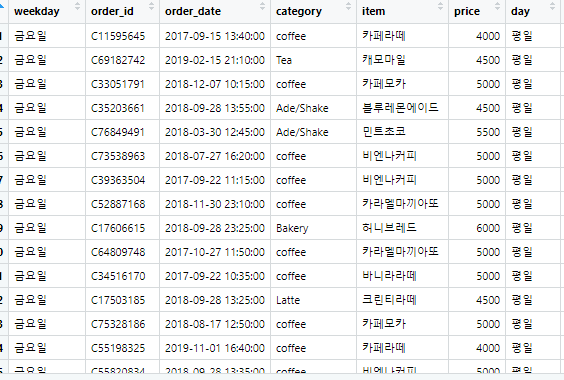
잘 나오네요 ㅎㅎ
1
2
3
4
5
6
7
8
9
10
11
#계절별 판매 분석
sales$month <- months(sales$order_date)
sales$month<- as.integer(gsub('월', '', sales$month))
sales$season <- ifelse(sales$month >=12,"겨울",ifelse(sales$month>=9,'가을',ifelse(sales$month >=6,'여름',
ifelse(sales$month>=3,'봄',
ifelse(sales$month>=1,'겨울')))))
table(sales$season)
이번엔 계절별 판매분석입니다. months()를 이용하면 날짜를 ~월 이런식으로 값으로 만듭니다. 그래서 파생변수 month를 만들어서 다 넣었습니다. 그리고 gsub()으로 그 ~월에서 ‘월’을 지웠습니다. 그리고 as.integer()로 정수화 시켰고요. 그리고 다시 파생변수 season을 넣은 뒤 복수의 조건문으로 각 월의 숫자를 구간을 나눠서 각각 사계절을 넣도록 했습니다.
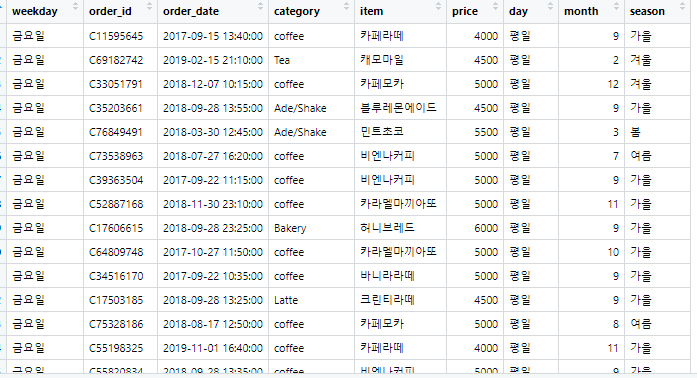
보시면 맨 오른쪽에 season이 잘 나오네요 ㅎㅎ
1
2
3
4
5
6
7
8
#시각화
cate<- data.frame(table(sales$category))
cate
library(ggplot2)
ggplot(cate,aes(Var1,Freq)) +geom_col()+geom_text(label=cate$Freq)
이번엔 sales의 category를 테이블 - 데이터프레임으로 변환하고 cate라는 변수에 넣었습니다. 그걸을 ggplot()에 자료값으로 넣고 aex()에는 x축, y축을 지정할 자료를 인자로 넣습니다. 그리면 전체 판이생깁니다. 여기에 geom_col()로 막대그래프를 만들었습니다. text()는 파이썬그래프때처럼 문자열을 출력하는 겁니다.
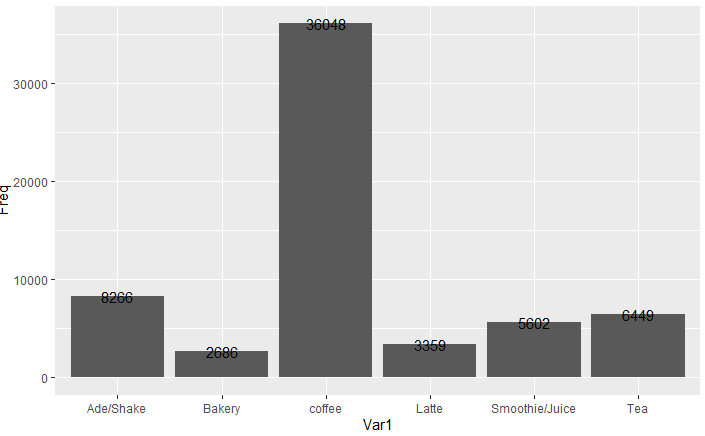
잘 나오네요 ㅎㅎ 재밌습니다!!
이번엔 여기까지 하겠습니다!
Comments powered by Disqus.