[Python] 크롤링(Crawling)
이번 시간에는 크롤링에 대해서 알아보겠습니다!
크롤링?
- 크롤러(crawler)는 자동화된 방법으로 웹을 탐색하는 컴퓨터 프로그램
‘웹 크롤링’(web crawling)??
‘데이터 크롤링’(data crawling)!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 다음 뉴스 페이지 크롤링
# url정의
url = 'https://news.daum.net/'
# requsts로 url에 정보요청
resp = requests.get(url)
# 정보를 html 변환 (보기 쉽게)
html = BeautifulSoup(resp.text, 'html.parser')
# html 내에서 뉴스헤더 선별
for news in html.select('a.link_txt')[:-13]:
html = BeautifulSoup(resp.text, 'html.parser')
for news in html.select('a.link_txt')[:-13]:
print(news.text.strip().replace('[', '').replace(']', ''))
다음 뉴스페이지에서 제목들을 가져와보겠습니다. url적고 bs로 html변환 한 것을 알 수 있습니다. 그런 다음 다음 뉴스페이지에서 개발자모드로 헤더를 가리켜서 원하는 태그를 얻어옵니다. 그리고 그 태그의 정보를 select()파라미터에 넣어줘서 가공한 다음 실행했습니다.

이런식으로 뉴스헤더가 잘 출력되는 모습을 알 수 있습니다~
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
lotto_list = []
for i in range(1, 31):
print(f'{i}회차 크롤링 중입니다.')
# 차단 방지
seed = np.random.randint(100)
np.random.seed(seed)
a = np.random.randint(5)
time.sleep(a)
# url 설정
url = f'https://search.daum.net/search?w=tot&DA=LOT&rtmaxcoll=LOT&&q={i}회차%로또'
# requests로 데이터 요청하기
resp = requests.get(url)
# html로 변환
html = BeautifulSoup(resp.text, 'html.parser')
# 데이터 선별
for ball_nm in html.select('span.ball')[:6]:
lotto_list.append(int(ball_nm.text))
print('크롤링 완료!!!')
이것은 로또 번호를 크롤링했습니다. 다음포털에 로또 번호를 위와 같은 방식으로 1회부터 30회까지 전부 한 리스트에 넣었습니다. 전부 한 리스트에 넣은 이유는 reshape으로 df형식으로 만들기 위함입니다!
1
2
3
4
5
6
7
lotto = np.array(lotto_list).reshape(-1, 6)
index_list = [f'{i}회차' for i in range(1, 31)]
df = pd.DataFrame(lotto,
index=index_list)
df
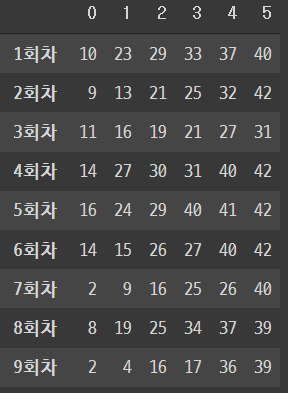
잘 나옵니다 ㅎㅎ
1
2
3
4
5
6
7
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 시각화까지
plt.figure(figsize=(12, 6))
sns.countplot(lotto_list)
plt.show()
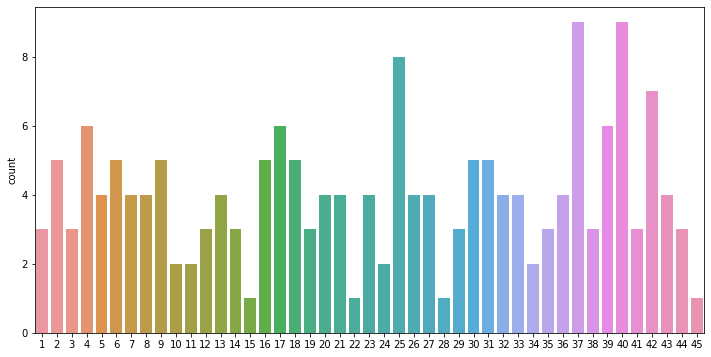
이렇게 countplot으로 각 번호의 빈출을 알 수 있습니다. 이렇게 차이가 나는 것은 표본이 30회차까지 밖에 없어서 그렇겠죠? 회차가 길어질수록 통계적확률에 다가갈 것입니다~
여기까지 하겠습니다!
This post is licensed under CC BY 4.0 by the author.
Comments powered by Disqus.