[EDA] 보스턴 부동산 가격 분석
오늘은 간단한 토이프로젝트처럼 보스턴부동산에 관한 데이터셋을 분석해봤습니다~ 보스턴 부동산 가격에 관한 유의미한 Factor를 찾아보려고 합니다.
EDA
- 다양한 각도에서 데이터를 관찰하고 이해하는 과정입니다. 데이터의 이해도가 높아지면서 숨겨진 의미를 발견하고 잠재적인 문제를 미리 발견할 수 있습니다. 이를 바탕으로 데이터를 보완하거나 기존의 가설을 수정할 수 있습니다.
1
2
df = pd.read_excel('/content/drive/MyDrive/Colab Notebooks/이어드림강의/2022-04-21(Toy)/BostonHousing.xls')
df.head()
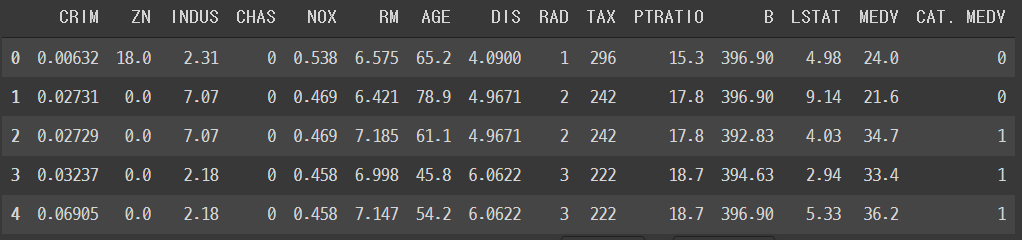
일단 파일을 가져왔습니다. 여기서 head()메서드로 간략하게 어떤 정보들이 들어있는지 확인합니다.
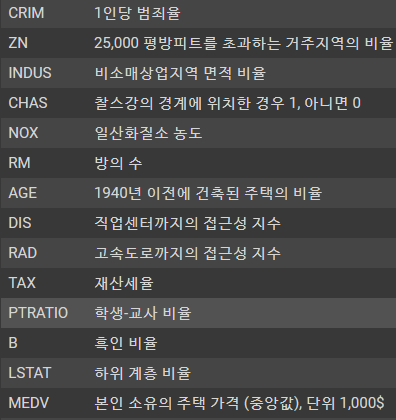
각 피쳐들에 대한 설명입니다. 우리는 여기서 저 MEDV 값에 영향을 주는 요인들을 찾아볼겁니다.
1
2
3
plt.figure()
sns.histplot( data=df, x="MEDV") # MEDV의 분포를 알아보기 위해 히스토그램으로 확인, 20000달러 주변에 많이 분포되어 있고 다만 50000달러 지표가 튀는 것 같아 조사가 필요해보임.
plt.show()
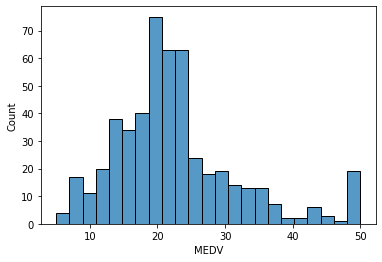
보니까 50이상은 다 50으로 한것같은데 자세히 보겠습니다.
1
df.loc[df["MEDV"]>=50]
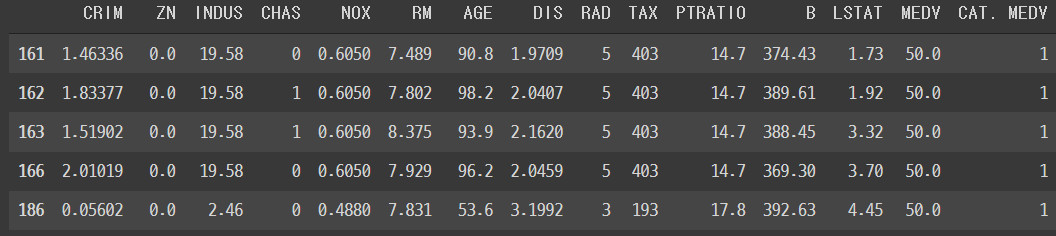
그렇네요. 50.0밖에 없는걸 보니 50이상은 50.0으로 바꾼 것 같습니다.
1
2
3
4
5
plt.figure(figsize=(10,10))
df_corr=df.corr() # corr() 메서드로 df의 상관관계 계수를 df_corr에 저장
sns.heatmap(data=df_corr, annot=True, cmap="Blues_r") # seaborn heatmap으로 df_cprr()를 시각화, annot을 True로 주어서 계수 눈으로 확인. cmap옵션으로 단색으로 설정
plt.show()
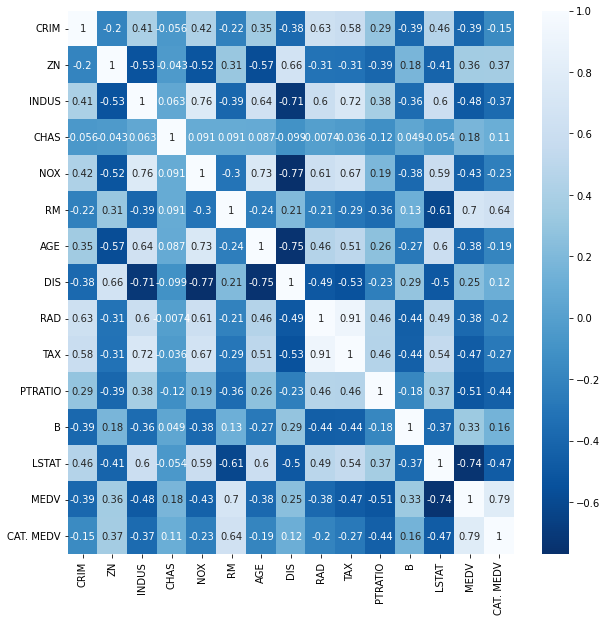
모든 지표들을 히트맵으로 찍어봤습니다. 저 MEDV에 유의미한 상관관계( 절대값 0.6이상)를 가지는 것은 RM과 LSTAT이네요. CAT. MEDV는 MEDV가 30이상인 row엔 1을, 그렇지 않은 경우는 0을 넣었습니다. 따라서 MEDV에 대한 2차 지표로서 당연히 관계가 있을 수 밖에 없습니다.
지표를 보니 상업지역들이 범죄율도 높아서 집값에 부정적인 영향이 있을 것 같긴 하지만 역시 상업지역이라 집값이 높은 부분도 많았습니다. 따라서 저는 상권과 비상권 지역으로 나누어서 다시 상관관계를 살펴보고 싶었습니다. 왜냐하면 부동산의 가격이 그 지역의 성질에 따라 영향을 받는 지표도 다른데 다 섞어서 한번에 보면 놓칠 수 있는 부분이 생길거라 생각했습니다.
1
2
3
plt.figure(figsize=(8,6))
sns.histplot(data=df,x="INDUS") #15를 기준으로 데이터 분포 군집이 있으므로 15이상을 상권지역이라고 판단.
plt.show()
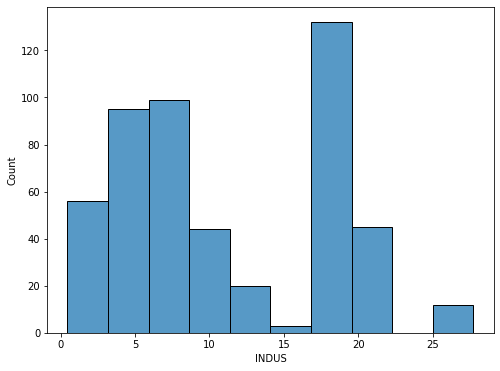
15를 기준으로 두 그룹으로 나누어봤습니다. 사실 나누는 것도 3분위나 4분위 지표를 구해서 하면 제일 좋았겠지만 이번엔 눈대중으로 해봤네요..ㅎㅎ..
1
2
3
4
5
6
7
8
9
10
# 비상권 지역 상관계수
df_low_INDUS= df.loc[df['INDUS']<15]
df_low_INDUS
plt.figure(figsize=(10,10))
df_low_INDUS_corr=df_low_INDUS.corr()
sns.heatmap(data=df_low_INDUS_corr, annot=True, cmap="Blues_r")
plt.show()
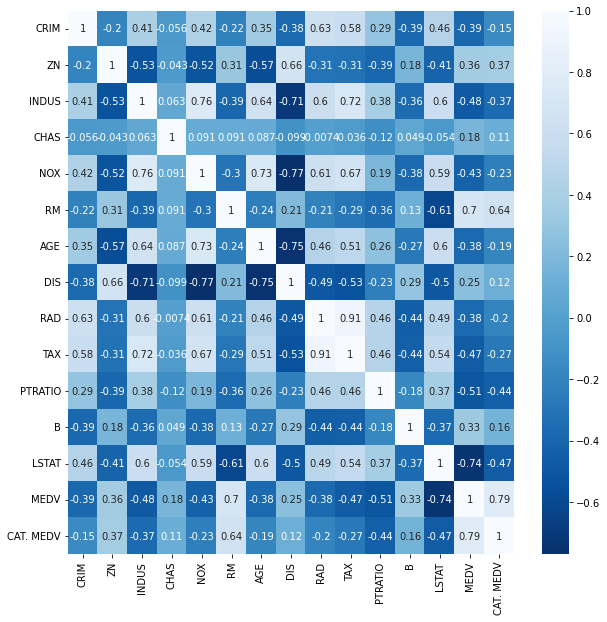
비상권 지역의 상관계수 히트맵입니다. 역시 RM(방의 개수)와 LSTAT(하위계층 밀집율)에 영향을 받네요.. 여기서 괜히 나눴나 생각했는데..
1
2
3
4
5
6
7
8
9
10
# 상권지역 상관계수
df_high_INDUS= df.loc[df['INDUS']>=15]
df_high_INDUS
plt.figure(figsize=(10,10))
df_high_INDUS_corr=df_high_INDUS.corr()
sns.heatmap(data=df_high_INDUS_corr, annot=True, cmap="Blues_r")
plt.show()
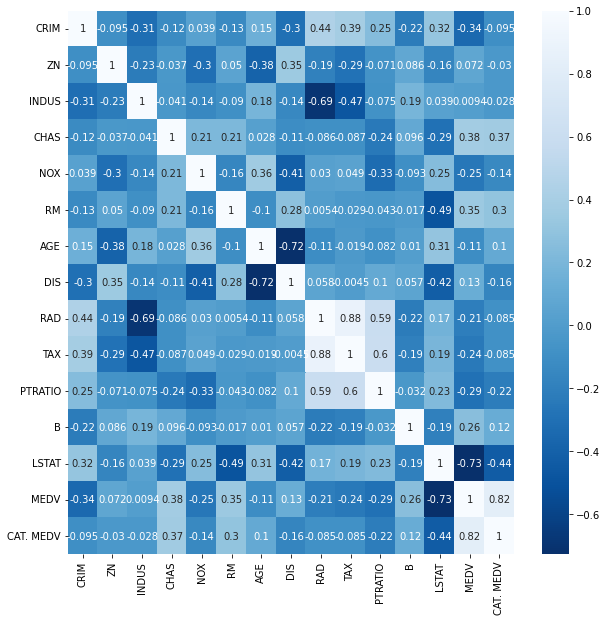
상권지역에서 다른 점이 보였습니다. 바로 RM인데요. 상권지역은 거주지역의 성격이 강하지 않고 부동산 가격이 비싸니까 잘게잘게 쪼개서 부동산 거래가 이루어지고 있나봅니다.(뇌피셜)
CAT. MEDV 에 따른 상관관계
아까는 상권으로 나눴는데 이번엔 CAT. MEDV로 나눠보겠습니다!
1
2
3
4
5
6
7
8
9
# CAT. MEDV가 1일 때
df_cat_1= df.loc[df["CAT. MEDV"]==1]
df_cat_1
plt.figure(figsize=(10,10))
df_cat_1_corr=df_cat_1.corr()
sns.heatmap(data=df_cat_1_corr, annot=True, cmap="Blues_r")
plt.show()
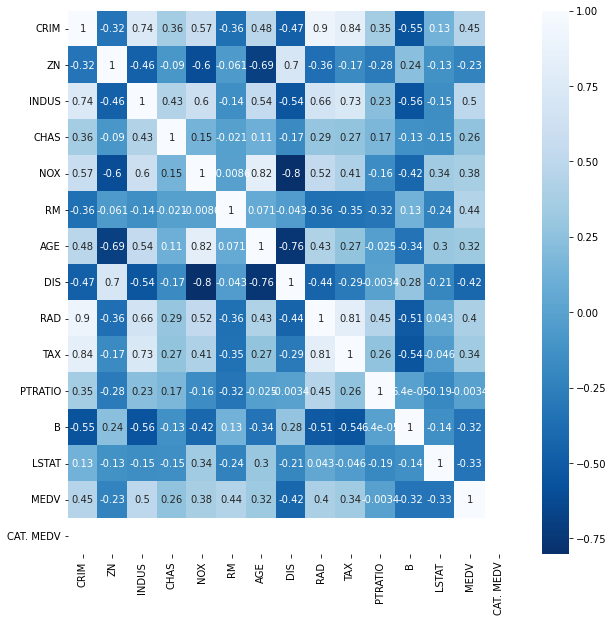
CAT. MEDV가 1일 때, 즉 3만달러가 넘는 지역에선 집값에 크게 영향을 주는 지표는 없었습니다.
1
2
3
4
5
6
7
8
9
# CAT. MEDV가 0 일 때
df_cat_0= df.loc[df["CAT. MEDV"]==0]
df_cat_0
plt.figure(figsize=(10,10))
df_cat_0_corr=df_cat_0.corr()
sns.heatmap(data=df_cat_0_corr, annot=True, cmap="Blues_r")
plt.show()
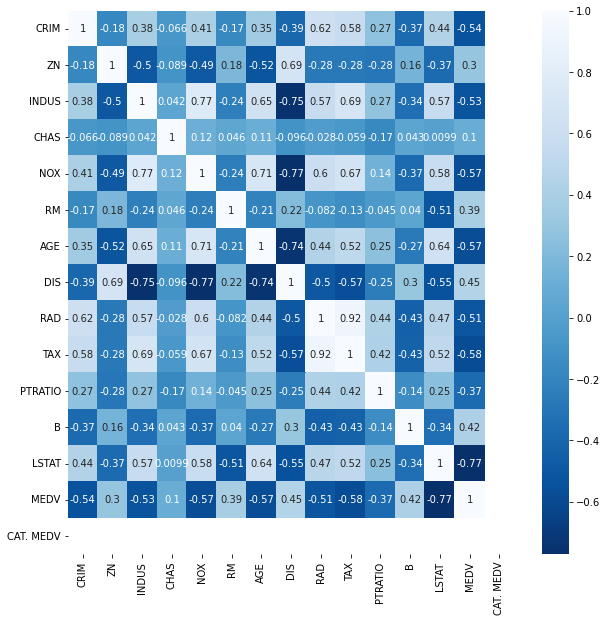
이번엔 그 지수가 0일때, 3만달러 미만의 부동산에는 여러가지 지표들이 영향을 끼친다는 사실을 알았습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
plt.figure(figsize=(8,6))
plt.subplot(2,2,1)
sns.scatterplot(data= df_cat_0, x="CRIM", y="MEDV")
plt.subplot(2,2,2)
sns.scatterplot(data= df_cat_0, x="NOX", y="MEDV")
plt.subplot(2,2,3)
sns.scatterplot(data= df_cat_0, x="AGE", y="MEDV")
plt.subplot(2,2,4)
sns.scatterplot(data= df_cat_0, x="TAX", y="MEDV")
plt.show()
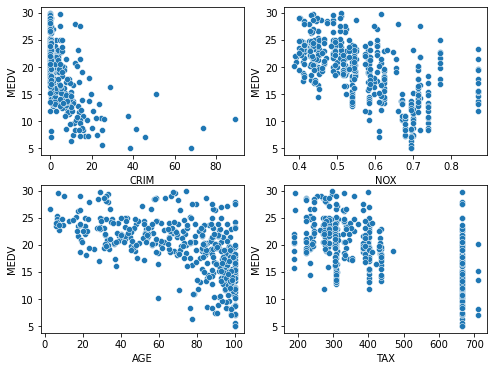
그중 영향이 큰 것 4개를 뽑아서 subplot으로 각각 살펴봤습니다. 그래프를 보니 뚜렷한 방향은 나타나지 않았군요..
혼자 해본 EDA였지만 재밌게 해봤습니다 ㅎㅎ
Comments powered by Disqus.