[C] 포인터
이번 시간엔 포인터에 대해서 포스팅을 하려고 합니다. 하기 전에도 C언어에서는 포인터 부분이 어렵다는 얘기도 많이 들었었고, 실제로 배울 때도 헷갈리는 점이 많았는데요. 한번 주욱 써보겠습니다.
메모리?
연속된 1byte 단위들의 공간들을 지칭합니다.
1 byte 단위로 데이터를 저장됩니다.
각 byte 데이터는 고유한 주소값을 통해 접근 가능합니다.
ex) int 값은 4byte 이므로 ‘연속된’ 1byte x 4개 공간에 저장됩니다~ 이것은 타입별로 그 값이 다르겠지요?
주소?
Windows 환경에선 주소는 4byte. (Mac 이나 Linux 에선 8byte) 이것은 타입과는 상관없이 정해진 고유값입니다 헷갈리지 않도록 주의하셔야 합니다.
주소연산자 : &
변수가 저장된 주소값을 리턴하는 연산자입니다.
int 같이 여러byte 에 걸쳐 저장된 데이터의 경우 첫번째 byte 의 주소값입니다. 시작점인거죠.
참조연산자 : *
포인터를 사용해서, 담고 있는 주소값을 찾아가 그 주소 안의 ‘값’을 참조합니다. 따라서 참조 연산자로 읽기, 쓰기도 가능합니다.
주소값 출력시는 %p 라는 지정자를 쓰면 됩니다.
변수명 앞에 & 사용하면 변수의 주소값으로 반환합니다. scanf문장을 쓸때 많이 썼죠?
%p 로 출력시 16진수 8자리로 표현합니다.(32bit, 4byte)
※ 16진수 2자리를 1byte 분량에 해당합니닷.
자 그럼 한번 visual studio에서 봅시다.

%d는 정수서식이고 %p는 주소서식이라고 말씀드렸죠. 따라서 %d에는 n값을, %p에는 &n으로 n의 주소값을 표현하도록 해보겠습니다.

주소는 저런식으로 16진법 (1~F)까지 나타나는 4byte(16진법에서 2자리수 = 1byte)형태의 수로 나타났습니다.
이제 포인터를 보여드리겠습니다. 보통 저희가 지금까지 한 것은 변수에 ‘값’을 보통 많이 넣어서 사용하였는데요, 포인터는 그 변수에 ‘주소’를 담습니다. 따라서 n의 값100이 아니라 n의 주소값이 있는거죠.
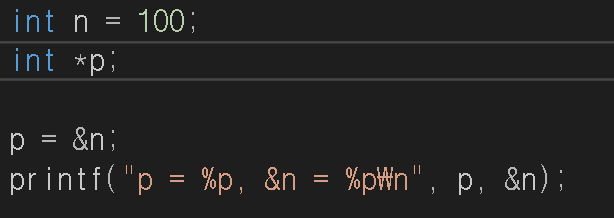
포인터 변수는 자료타입뒤에 *를 붙여서 사용합니다. 그래서 int* p는 int타입 포인터 변수이며 사진처럼 이를 선언한 것이죠. 그리고 p=&n;으로 포인터 변수 p안에 n의 주소값을 담았습니다. 그리고 그것을 확인하기 위해 printf문으로 확인을 해볼게요.

p와 &n값이 같죠? &n는 주소값의 표현이라 주소가 나오지만, p는 따로 &를 안 붙여도 그 자체가 주소를 담고있는 포인터 변수라 주소값이 나타난 겁니다. 이제 참조 연산자를 보도록 하죠.

printf문으로 정수서식자에 *p를 출력하도록 했습니다. *는 참조 연산자로 위에 말씀드렸죠? 그 포인터 변수가 가리키는 주소(다른 변수의 주소)를 찾아가서 그 주소 안의 ‘값’을 읽고 쓰는 것이라고 했습니다. 실행해보죠.

*p는 p의 주소값을 찾아서 읽습니다. p는 n의 주소값을 담고 있죠? 그래서 n을 찾아가서 그 ‘값’(100)을 출력한 것입니다. 신기하죠?
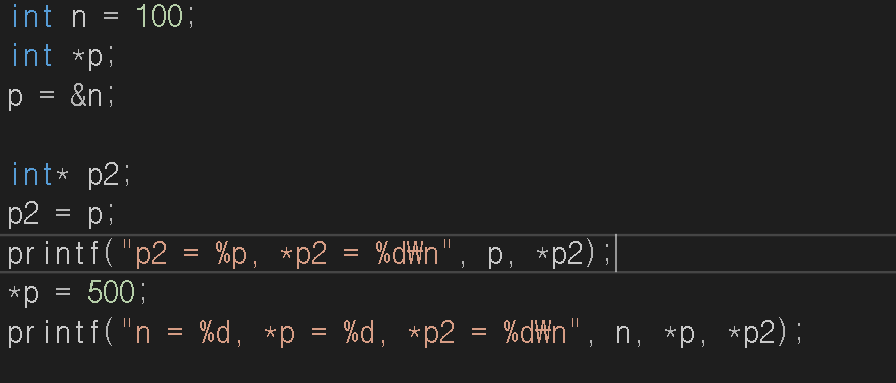
이번에는 또다른 포인터 변수 p2를 만들었습니다. 그리고 p의 주소값도 p2에 대입하였습니다. 그러면 p2도 p가 가리키는 것을 가리키겠죠?(pointing) 자 거기에다 아까 참조 연산자는 읽기도 되지만 쓰기도 가능하다고 했죠?
*p=500; 을 썼습니다. 이게 무슨 뜻이냐면, p가 가지고 있는 주소값으로 가서 그 값을 500으로 대입시킨다는 것이죠. printf문 2개를 쓸건데 *p=500; 전후로 나눠서 그 결과값을 한번 봅시다.

p2가 가지고 있는 주소값은 p와 같을 테고, 처음 p2의 참조값은 100이 나왔죠.. 그리고 위의 참조연산자를 하고 난 뒤에는 n,*p,*p2 값이 전부 500으로 되는 것을 볼 수 있습니다.
*주의 할점은 포인터에 직접 숫자값을 대입하는 것을 매우 위험합니다. 예를 들어 포인터 변수로 선언된 p에 p=100; 이런식으로 써버리면 말그대로 참조값이 아닌 주소값 자체가 100으로 되버리기 때문이죠!
포인터연산
포인터 연산에 들어가기 전에 중요한 것 3가지 짚고 넘어가죠.
포인터 변수에는 주소가 들어갑니다.
*포인터에는 그 주소가 가리키는 값을 나타냅니다.
포인터 타입은 그 주소가 가리키는 값의 타입을 나타냅니다.
따라서 포인터변수에 +,- 연산을 하는 것은 결국 그 주소값을 증감 하는 것입니다. 그리고 주소값이 얼마만큼 증감 하느냐는 ‘포인터 타입’에 따라 다릅니다.
int*(int타입 포인터)인 경우 가리키는 값의 타입이 int(4byte)이기 때문에 포인터 값에 +1연산을 할 경우 주소값이 4증가합니다.

새로 만들었습니다. 정수타입 n에 555값을 대입하고 포인터 변수p에는 그 n의 주소값을 대입했습니다.
그러면 첫번째 printf문에서는 n의 값과 n의 주소값(p)와 *p값을 출력하고 두번 째에는 n+1과 p+1가 갖고 있는 주소값과 *(p+1)과 *p+1을 각각 출력했습니다.
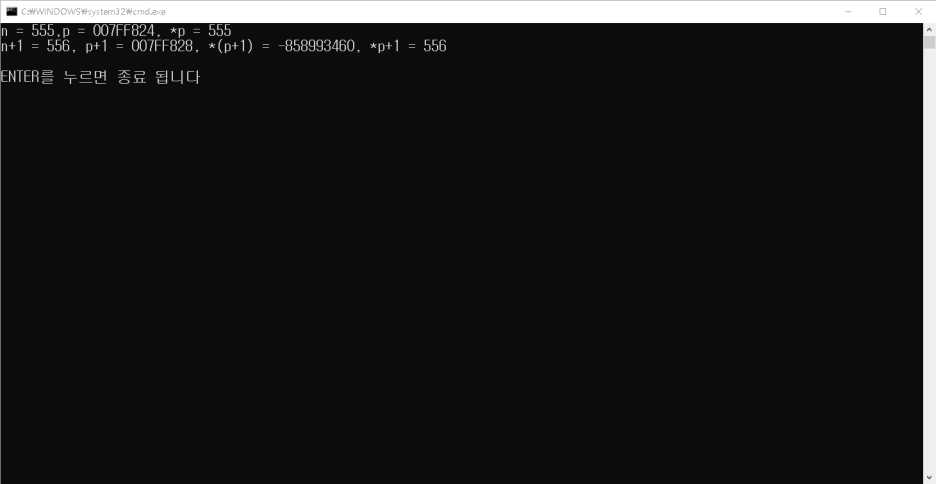
n+1은 기존 555에서 556으로 되었구요 p+1을 봅시다. 기존 n의 주소값에 4가 더해진 모습을 볼 수 있나요? 주소값이 얼만큼 증감하는지는 타입에 따라서 다르다고 했지요? int 타입은 4byte입니다. 따라서 p+1의 값은 기존의 p의 주소값에 4byte가 더해진 모습을 확인할 수 있습니다. 그리고 *p는 555니까 *p+1은 556이 되겠구요.. 한 가지 이상한것은 *(p+1)인데요.. 아까 p+1은 기존의 주소값에 4byte가 더해진것이죠? 우리도 모르는 주소를 가리키고 있고 그 주소에 들어있는 값은 예전에 말씀드린 ‘쓰레기 값’이 나왔습니다. 따라서 포인터 연산할 때에는 괄호같은 연산 순서에 대해서 정확하게 파악하고 있어야 하겠죠.
int 타입은 4byte씩 증가 했으니 short는 2, double은 8byte씩 증가하겠죠?
포인터와 배열
제가 비밀을 하나 말씀드리겠습니다.. 사실 배열은 포인터의 또다른 이름입니다! 포인터’상수’인 격인데요.
따라서 똑같은 포인터 연산이 적용딥니다.
배열첨자 연산자 [ ] 는 결국 포인터 연산입니다. 여기서 중요 공식을 말씀드리고 차근차근 설명해보겠습니다.
arr[n] <-> *(arr +n) ★★★★★

제가 배열을 하나 만들었습니다. int타입이고 배열원소의 개수는 3개, 각각 10,20,30의 값을 대입했죠.
그리고 그 주소값을 하나하나 보았습니다. 여기서 그냥 배열의 주소는 &가 안 붙고 원소, 즉 arr[n]에는 &가 붙는 이유는 배열자체는 포인터고 원소는 int타입의 정수값이기 때문입니다.

신기한것은 원소들끼리 그 주소값이 4씩 증가한다는 것과, arr[0]과 arr의 주소값이 같다는 것을 확인할 수 있는데요, 이는 어떤 배열의 주소값을 나타날 때에는 첫번째 원소값의 주소, 즉 시작점을 나타낸다는 것입니다.
포인터 연산도 똑같이 배열에 적용되는데요.

두 printf문 집합을 만들었는데요. 첫번째 덩어리들은 arr+ 0~2 까지의 주소값을 나타내는 것이고 이것은 &arr[0~2]와 같습니다. 따라서 두번째 덩어리에서는 참조연산자로 *(arr +0~2) 한것도 arr[0~2]의 정수값과 똑같이 나오는 것을 볼 수 있죠.
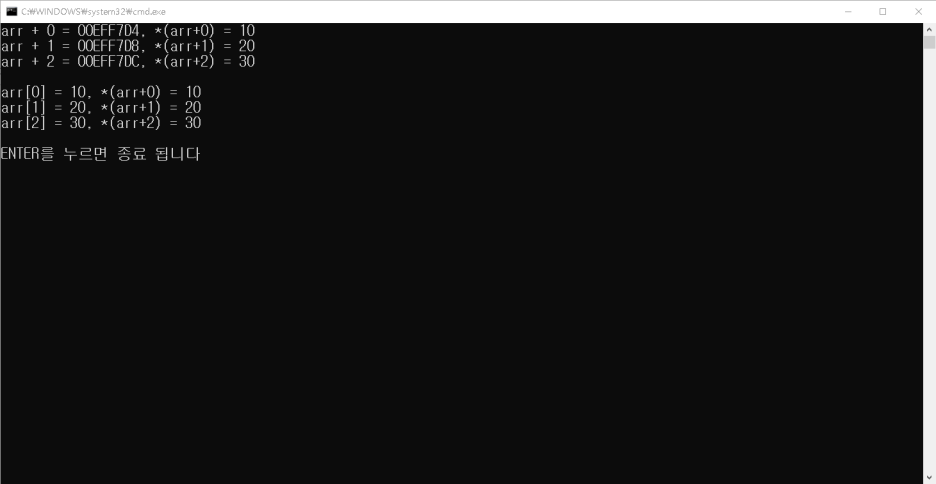
똑같죠? 따라서 위의 공식이 성립한다는 것을 알 수 있습니다.
그리고 다른 포인터 변수로 배열자체를 가리킬 수 있습니다. 이렇게 하면 포인터 변수 p는 아예 배열 p처럼 작동하게 되죠.


p가 arr배열과 똑같이 나오죠? 재밌습니다 ㅎㅎ
자, 그럼 근본적인 질문.
배열이 있는데 왜 포인터변수를 사용하나요? 배열과 포인터 변수의 차이점은?

데이터의 크기가 다릅니다. sizeof(p)를 하면 p는 arr의 배열을 담고있으니 똑같이 배열원소의 개수(3)과 하나당 int타입이니까 4byte씩, 즉 12byte가 되어야 하는데 출력하면 그냥 4byte로 나옵니다. 그 이유는 모든 포인터 주소 용량은 타입과 상관없이 4byte이기 때문이죠. 이는 실로 차이가 큽니다. 메모리에서 실행하는 용량이 작아지니 그만큼 빠른 연산이 가능하다는 점이죠! 그래서 포인터를 사용하면 더 효율적인 작업을 기대할 수 있게 됩니다.
이중포인터
순환문에도 이중 순환문이 있고, 배열에도 2차,3차 .. 배열이 있듯이, 포인터에도 이중포인터가 존재한다.

정수타입 num1 을 0으로 선언 및 초기화 한 후, 마찬가지로 포인터 변수 p와 이중포인터변수 pp를 선언했습니다. int **pp를 굳이 나누자면, int* *pp라고 할 수있습니다. 결국 int 타입의 포인터 변수이죠. NULL이라는 것은 보라색으로 되어있는데요, 보통 상수값 색이 저렇습니다. NULL은 따로 선언하지 않아도 됩니다. 아무것도 없는 값이죠. 그 후, p에는 num1의 주소값을 넣고 pp에는 그 p의 주소값을 넣습니다. 따라서 **pp는 p로 갔다가 다시 num1로 가야하니까 두번 참조하라는 뜻으로 **로 작성합니다. 프린트문으로 몇가지를 살펴보죠.

처음수는 num1값이 나왔죠? 그다음엔 num1의 주소가 나왔습니다. 그다음은 %p서식자에 pp를 넣었죠? pp는 p의 주소값을 담고있으니까 p의 주소값이겠네요. 그 다음줄을 봅시다. 첫번째는 %p서삭자에 &p를 넣었네요. 따라서 num1의 주소값이 아니라 p그 자체의 주소값을 나타냈네요. pp가 담고있는 주소값이랑 같죠? 그 다음줄을 보죠.
num1의 값과 p와 pp의 참조값을 다 출력했습니다. 전부 0으로 동일하네요! 재밌습니다 ㅎㅎ
전달 방식에 따른 함수호출
1. Call By Value(값에 의한 호출)
기본적으로 매개변수 값의 ‘복사’가 발생합니다. 따라서 호출한 원본의 변화는 없습니다.
2. Call By Reference(참조에 의한 호출)
호출시 포인터(주소)를 함수에 넘겨줍니다. 기본적으로 매개변수(포인터,주소) 값의 ‘복사’가 발생합니다. 따라서 주소를 따라가서 호출한 원본의 변화를 발생시킵니다.
이렇게 말하니까 헷갈리네요.. 직접 해봅시다. 먼저 값에 의한 호출을 보죠.
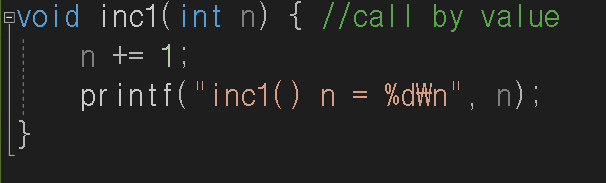
main()함수 밖에 inc1이라는 함수를 만들었습니다. n값에 1씩 증가시키고 그 n값을 출력하는 함수네요.

그리고 main()함수에 이렇게 적어봤습니다. n의 값은 10으로 선언하고 inc1(n)함수를 두번 실행시켰습니다. 그렇다면 n의 값은 어떻게 될까요? 10? 11? 12?

놀라운 포인트는 2개입니다. 일단 2번실행시켰는데 둘다 n의 값은 11이었고, main()함수에서 n값을 출력할땐 초기값 10이 호출 후에도 출력이 되는군요. 그 이유는 위와 같습니다. 값을 복사만 했기 때문에 원본값은 바뀌지 않습니다. 또한 두 n이 같다고 할 수 있을까요? 하나는 main()에 있고 하나는 inc1에 있는 이름만 n으로 같을 뿐이지 서로 다른 지역변수 입니다. 따라서 inc1에서 n이 증가했다하더라도 main()함수에 있는 n값은 변함이 없기에 몇번을 호출해도 n=10의 값이 inc1함수에 들어가서 11이 출력하는 것이랍니다!!

inc2라는 함수를 만들었습니다. 여기에 매개변수는 int타입의 포인터변수 p구요 여기에는 당연히 주소값이 들어가겠죠? 함수는 그 주소값을 참조하여 거기에 1을 더하고 그것을 출력하는 함수네요.

그리고 main()함수에서 inc2를 사용하고 n의 주소값을 넣었습니다. 과연 어떻게 될까요? inc2함수를 사용하고 난 뒤 main()함수에 있는 n의 값을 변화가 있을까요?

inc2함수를 실행시켰습니다. n의 주소값을 참조하여 그 값에 1을 더한것을 잘 출력했네요. 문제는 그 다음입니다. 호출한 후 main()함수에 있던 n의 값에는 변화가 생겼습니다. 왜일까요? 단순히 ‘값’을 복사한것이 아니라 n이 가지고 있는 고유의 ‘주소값’을 복사하여 참조하였기 때문입니다. 따라서 그 주소로 갔으니 원본n으로 찾아갔겠지요.. 그래서 그 값을 갖고 놀았으니 변동이 있는겁니다.
이번에는 포인터에 대해서 적었습니다. 꽤 길었지만 정말 재밌었습니다 ㅋㅋ
Comments powered by Disqus.